训练ChatGPT模型不付钱?美国新闻集团拟起诉微软、谷歌、OpenAI
更新时间:2023-03-23 23:26:33作者:cblsl
3 月 23 日消息,自 ChatGPT 风靡全球后,AI 版权问题就成为近来国外争论不休的一个焦点。

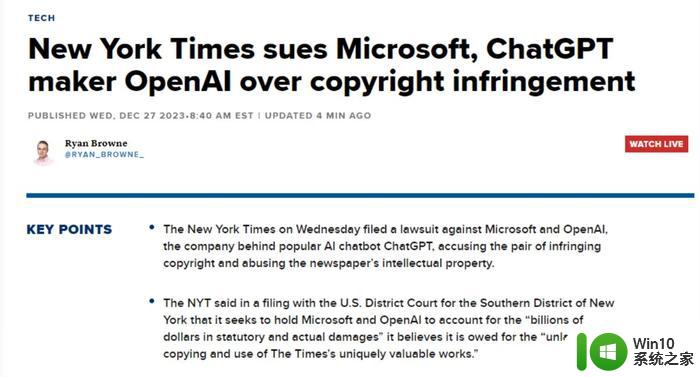
据华尔街日报报道,AI 技术的发展已经引发了新闻出版业的不满,他们认为自己的内容被大型科技公司用于训练 AI 模型而没有得到合理的补偿。拥有《纽约邮报》、《巴伦周刊》、《华尔街日报》等的美国新闻集团正准备向 OpenAI、微软和谷歌等公司提起诉讼,要求赔偿其内容在 ChatGPT、Bard 等 AI 工具中被用来使用的费用。
当前这是一个复杂而模糊的法律问题,涉及到 AI 公司是否有权从互联网上抓取内容,并将其输入到训练模型中。一些批评者认为,这是一种工业规模的知识产权盗窃行为。出版商担心,AI 工具可能会影响他们网站的流量和广告收入。
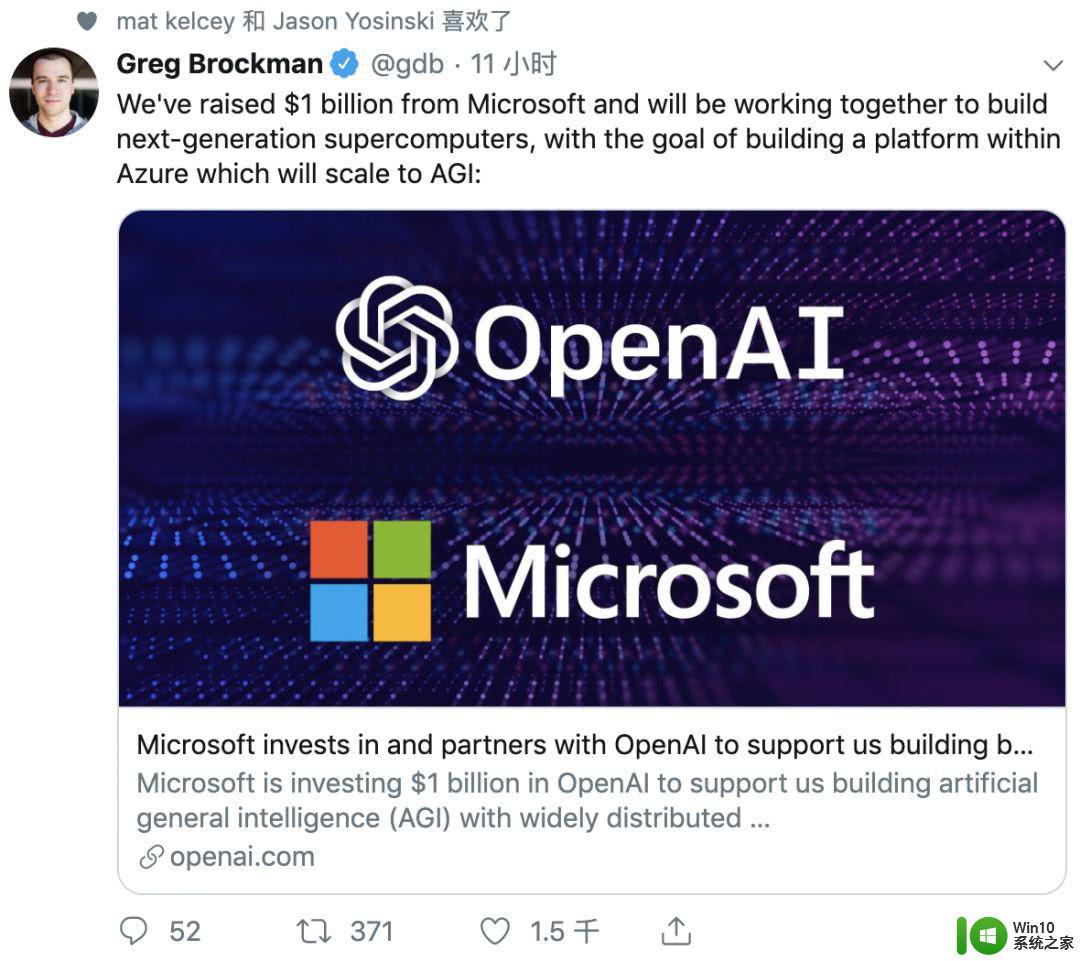
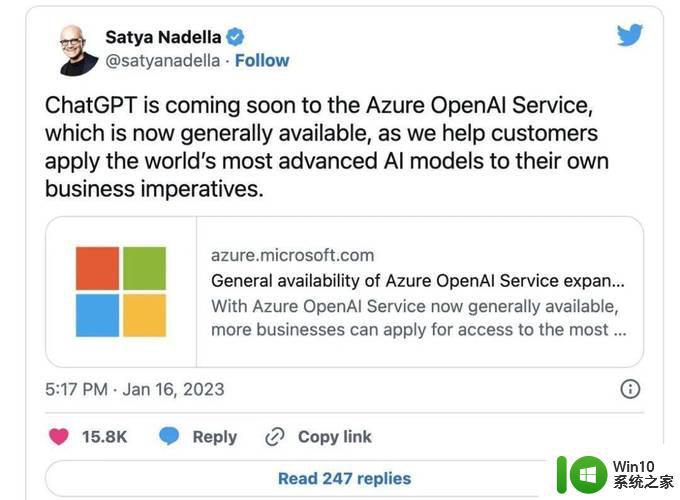
事实上,AI 版权问题并非始于 ChatGPT。注意到在图像和代码方面,已经有多起诉讼案件涉及到 AI 模型训练使用受版权保护的数据。例如,Midjourney、Stability AI、微软、GitHub 以及 OpenAI 都曾卷入相关纠纷。
目前,对于 AI 创作是否受版权保护还没有形成固定的准则。法律人士认为,所有针对生成式 AI 的案件可能需要数年时间才能结案。科技公司与内容出版商进行协商寻求使用许可,或许是最好的解决办法。