训练ChatGPT模型不付钱?文字版权商怒了:微软、谷歌、OpenAI,法院见!
自ChatGPT风靡全球后,AI版权问题一直是一个担忧。AI模型的训练需要大量数据和内容,但其中许多有版权归属,AI公司是否该为使用这些内容付费,成为近来国外争论不休的一个焦点。
据《华尔街日报》3月22日报道,拥有《纽约邮报》、《巴伦周刊》、《华尔街日报》等的美国新闻集团正准备通过法律程序向技术制造商如OpenAI、微软和谷歌要求赔偿。
有关这类讨论的一个核心问题是,AI公司是否有权从互联网上抓取内容,并将其输入到训练模型中。一些批评者认为,AI 技术使工业规模的知识产权盗窃成为可能。
《每日经济新闻》记者注意到,同类诉讼已经涉及到在AI模型中使用图像和代码数据进行训练的问题。例如,Midjourney 、Stability AI、微软、GitHub以及OpenAI都曾卷入相关诉讼案中。若美国新闻集团对微软、谷歌、OpenAI提起诉讼,将是第一起针对文本类的相关案件。
不过, AI工具仍处于进入商业应用的早期,对版权问题还没有形成固定的准则。AI公司是否有权从互联网上抓取内容并训练模型,也是一项模糊不明的法律问题。法律人士认为,所有针对生成式AI的案件可能需要数年时间才能结案。随着科技公司自身也更加注意到版权问题,与内容出版商达成协议寻求使用许可,或许是最好的解决办法。

图片来源:视觉中国-VCG111421248465
不付钱随便用?文字版权商怒了《华尔街日报》援引一位熟悉媒体联盟组织(The News Media Alliance)的人士称,最近几周。一些新闻业高管已经在研究他们的内容在多大程度上被用于训练ChatGPT、Bard等AI工具,并正在探索如何通过法律途径获得补偿。“我们拥有有价值的内容,这些是人工辛勤劳作的结晶,但这些内容不断被用于为其他人创造收入,因此必须得到补偿,”该组织在接受采访时这样说道。
3月21日,谷歌公司推出了聊天机器人Bard测试版本,以期追赶ChatGPT。不过,在推特网友进行的早期测试中,Bard提供的答案通常不会给出基础新闻来源的链接。例如,当被要求提供《纽约时报》最大新闻的摘要时。Bard回应了一份清单,在答案结尾它给出“有关这些和其他故事的更多信息,请访问纽约时报网站”的提示,但没有提供答案的链接或引用。
这类事件引起了许多内容发布商的关注。美国社交网站Reddit已与微软就后者在AI模型训练中使用内容的情况进行了会谈。
美国新闻集团NWSA首席执行官Robert Thomson在最近的一次投资者会议上表示,“已经开始与某一方进行讨论。很明显,他们使用的是专有内容——显然,应该为此提供一些补偿。”
《华尔街日报》评论称,AI工具的出现加剧了大型科技公司与出版界之间本已紧张的关系。一直以来,出版商依赖谷歌、Meta等科技公司的帮助,以使其内容覆盖更广泛的受众。但与此同时,也有越来越多的出版商要求科技公司为使用其内容而付费。
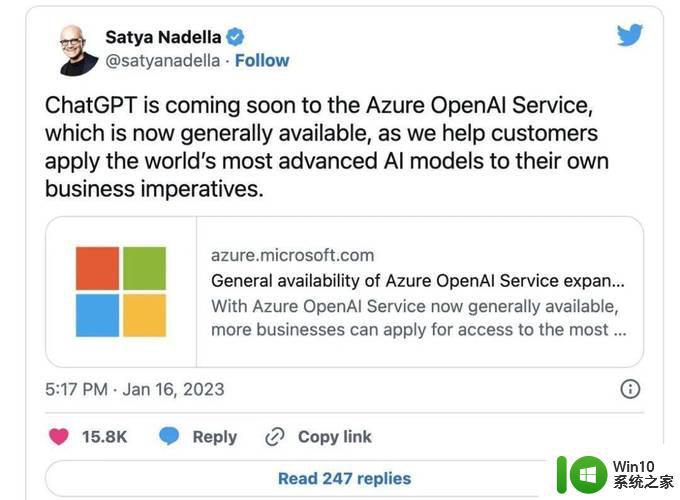
出版商担心的是,AI工具可能会耗尽他们网站的流量和广告费用。 尽管微软首席执行官Satya Nadella表示,“一切都是可点击访问的”,不过一些出版业高管表示,有多少用户会真正点击这些链接并访问他们的网站,这是一个悬而未决的问题。
据报道,在美国、日本、欧盟等地的法律中,均有“合理使用”条款,允许个人、公司在某些情况下未经许可使用受版权保护的材料。许多AI公司也援引这一条款为自己申辩,但出版商则认为,大量使用受版权保护的内容训练AI,是对这一特许权利的滥用。
图像、代码类诉讼已屡见不鲜在AI工具如何合理使用已有内容的争论中,一个核心的问题是,AI公司是否有合法权利从互联网上抓取内容,并将其输入到训练模型中。一些批评者认为,AI技术使工业规模的知识产权盗窃成为可能。
实际上,AI训练产生的版权担忧并非始于ChatGPT。2022年,OpenAI 推出的Dall-E 2、Stability AI 创建的Stable Diffusion以及由Midjourney发布的同名AI图像工具掀起了图像AI的风潮。
在这些AI工具中,许多作品通过模仿一些摄影图片或知名画作的风格而生成。为了让算法能够模仿这些风格,构建它们的公司首先必须从互联网上复制这些作品,然后用其来训练AI模型。因此,这些公司也由于版权问题而卷入一桩又一桩的诉讼案中。
今年2月,Getty Images在特拉华州起诉了Stability AI,指控其侵犯图片版权;1月,以画家Grzegorz Rutkowski为首的一批艺术家作为原告对Midjourney、Stability AI提起了集体诉讼。
更早之前,去年11月,美国加州的联邦法院也提起了一项集体诉讼,针对微软及其子公司GitHub和OpenAI的GitHub Copilot系统。原告称,该系统生成了不注明原作者姓名的代码,违反了各种开源许可以及《数字千年版权法》。
负责前述针对微软和GitHub案件的律师Joseph Saveri认为,美国司法部在1990年代成功起诉微软的反竞争行为(例如将Internet Explorer网络浏览器与Windows操作系统捆绑在一起),与今天有一些相似之处。现在和那时一样,他看到微软正在迅速采取行动,以主导它认为对下一代互联网和计算很重要的领域。
到目前为止,同类诉讼已经涉及到在AI模型中使用图像和代码数据进行训练的问题,但还没有出现涉及文本类内容的重大案件。也就是说,如果此次美国新闻集团对微软、谷歌、OpenAI提起诉讼,将是第一起针对文本内容的案件。

图片来源:视觉中国-VCG41N817744988
相关立法预计将引入实际上,科技公司自身也已经注意到了AI训练中所涉及的版权问题。与内容出版商达成协议寻求使用许可,或许是最好的解决办法。
OpenAI首席执行官Sam Altman曾表示,“我们在合理使用方面做了很多工作”。他透露,OpenAI将在必要时就内容达成交易。“我们愿意为某些领域非常高质量的数据付出高昂的代价,”他这样说道。
在OpenAI已经达成的商业协议中,Sam Altman提到了去年秋天与在线图库Shutterstock达成的一项协议。OpenAI从 Shutterstock获得数据许可,并且Shutterstock开始使用 OpenAI 技术。 与此同时,Shutterstock 设立了一个基金,为那些作品被用于AI训练的艺术家提供补偿。
据报道,谷歌方面已经达成协议,向包括新闻集团在内的一些出版商支付费用,以在Google News Showcase的产品中使用他们的内容,不过该产品尚未在美国推出;多年来,微软一直为其MSN平台的内容向出版商付款,但这些交易目前还不包括AI产品。
华盛顿大学的法律学者Inyoung Cheong表示,法院在判决时,要权衡这类新技术在使用这些内容时的潜在危害和好处,所有针对生成式AI的案件可能需要数年时间才能结案。
在法律层面,据知情人士透露,允许美国出版商在不违反反垄断法规的情况下进行集体谈判的立法预计将很快引入,该立法将涵盖AI工具对受版权保护内容的合法使用。
上周,美国版权局表示,已经发起一项研究AI工具的倡议,包括在AI模型训练中对受版权保护内容的使用。
每日经济新闻