极致堆料,旗舰配置,iGame GeForce RTX 4080 Vulcan OC首发显卡评测
1引言&规格&外观
引言
硬件圈有两个春晚,一个是苹果发布会,另一个就是NVIDIA的显卡发布会,前不久RTX4090的强劲性能给大家留下了深刻的印象,首发上市也是一抢而空,而次旗舰RTX4080历尽波折也终于来了。全新AdaLovelace架构以及换用TSMC4N工艺让这一代RTX4080显卡性能获得飞跃,各家AIC厂商也纷纷推出自家重量级的RTX4080显卡。

想必现在很多玩家迫切的想知道RTX4080显卡表现如何,笔者也在第一时间拿到了七彩虹旗下的高端显卡——iGameGeForceRTX4080 16GB VulcanOC,玩家更喜欢称之为“火神”,iGam旗下的双雄之一,那它的性能究竟表现如何,让我们接着往下看。
*下方“iGameGeForceRTX4080 16GB VulcanOC”将简称为“iGame GeForce RTX 4080 火神”
规格对比
在开始之前,先了解一下本次的主角RTX4080,其采用的是AD103-300核心,TSMC4N工艺制造,芯片面积为379平方毫米,晶体管密度达到了459亿,晶体管数量相比较于上一代产品提升非常明显,近乎翻倍,而这一代的核心还进一步提升了频率,因此能带来更好的性能表现。
其他参数方面,RTX4080RTX4080标配9728个CUDA,128个第三代RTCores,512个第四代TensorCores,并且用上了16GB的GDDR6X显存,大显存配合性能上的提升更可以为游戏以及创作者带来更好的使用体验。
而目前RTX4080显卡配备的AD103-300核心并不是完整的AD103核心,完整的AD103核心应该包括7个GPC(图形处理集群)、40个TPC(纹理处理集群)、80个SM(流式多处理器)以及一个带有8个32Bit显存控制器的256Bit显存带宽。因此笔者猜测,RTX4080或许不是AD103核心下的终极产物,后续应该还会推出完整AD103核心的RTX4080Ti。
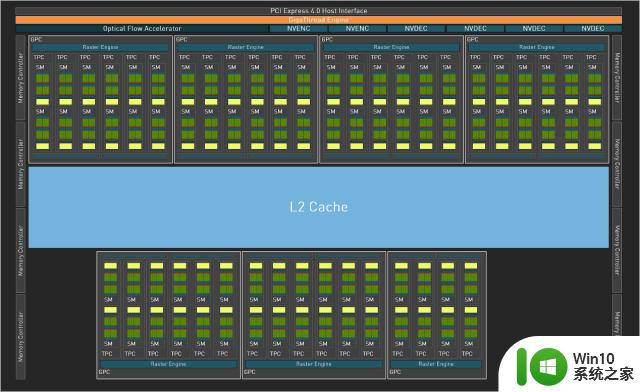
再看看下方的RTX4080的核心结构图,和完整版本的AD103核心对比起来就很容易看出差别,RTX4080核心代号为AD103-300,其拥有4个完整规格的GPC(图形处理集群,每个内建6个TPC),与3个非完整的GPC(两个内建5个TPC,一个内建4个TPC),共组成38个TPC,SM单元则剩下76个,显存位宽还是完整的256Bit。
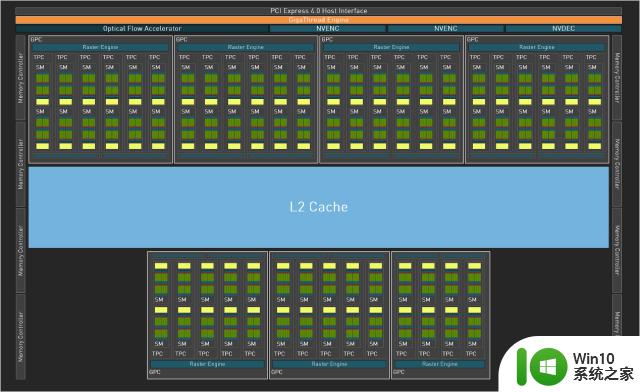
但是RTX4080上的AD103-300核心在编解码器上砍了一刀,不得不说老黄的刀法精准,编解码器数量直接砍半,与RTX4090同等规格,仅保留了两个NVENC编码器和一个NVDEC解码器,因此完整版的AD103核心应该会有更快的视频编解码速度,不过之前测试过RTX4090,编解码速度相比上一代有着近乎翻倍的提升,想必RTX4080也有不错的表现。
外观赏析:七彩虹iGame GeFore RTX 4080 16GB Vulcan OC
作为七彩虹旗下的旗舰产品,七彩虹iGame GeForce RTX 4080 火神的外包装甚至比一些RTX4090的还要大,正面印有iGame的Logo以及GeForceRTX4080字样,包装盒的正面是疾驰而来的iGame GeForce RTX 4080 火神,设计相当有特色。

包装背部则是这一代显卡用到的技术,如:智屏、全新设计的散热系统、iGame控制中心等。

打开包装,引入眼帘的正是七彩虹的新主张——“我游自在”的游玩体验新境界。

显卡全部附件包括一个可拆卸的智屏以及底座、新的灯光组件、4*8Pin转16Pin延长线、灯光同步线、显卡支撑以及用于拆解显卡的配套螺丝刀。

外观上,七彩虹iGame GeForce RTX 4080 火神主打后赛博时代,造型极具赛博朋克风,棱角分明的线条搭上硬朗的金属框架,从内而外都透露着未来科技感。

七彩虹iGame GeForce RTX 4080 火神的散热系统经过重新设计,配备了新一代的旋涡(Vortex)散热系统,正面是三个104mm散热风扇,被锖铁色金属外骨骼牢牢框住。其采用的“聚风镰环”扇叶能帮助风量进一步集中,有利于带出热量。


显卡顶部印有GEFORCERTX字样,底下则是一整排的出风口,横跨整个显卡顶部和底部,加速热量排出。


显卡背板设计也很带感,金属一体背板加持,进一步加强显卡强度,金属拉丝工艺加上亮面的iGameLogo与正面的赛博朋克风不谋而合。

在背板末端还留出了镂空散热窗口,使用了“真空冰片”技术的导流型鳍片,导流型鳍片拥有更大的间隙,更利于风流进入,加速内部气流循环。

供电用的是全新的12VHPW供电接口,通过一根12VHPW的电源线就可达到供电需求,如果用户使用的是ATX2.0标准的电源,也可以使用附赠的4*8Pin转16Pin延长线来进行使用。


底部为显卡金手指,接口为标准的PCIe4.0x16,在使用前一定要在主板打开ResizableBAR功能,这张显卡的性能才能完全释放。

不同于RTX4090动辄3.5槽的厚度,七彩虹iGame GeForce RTX 4080 火神的实际厚度仅有3槽,并且配备了三个DP1.4a和一个HDMI2.1a,用这张卡带8K显示器也是一点问题没有。

显卡自带两个不同的BIOS,其中一个主频与RTX4080FE看齐,为2505MHz,TURBO版BIOS主频默认可以来到2640MHz,实际测试中约在2800MHz左右。

除了配置上的豪华,性能提升的亮眼,这一代七彩虹iGame GeForce RTX 4080 火神在外观和交互上也标新立异,引入了全新的智屏,为玩家带来了更多的可玩性。

虽然在之前的VulcanOC系列显卡上,七彩虹早就配备了侧边屏幕,不过七彩虹iGame GeForce RTX 4080 火神上的这块智屏是经过全面升级的,采用的是可拆卸可替换的设计,并且进行了分辨率的提升。这一块屏幕的分辨率由上一代产品的480*128PX提升至800*216PX,显示的内容可以更加细腻,更加具有视觉冲击力。

智屏支持在显卡上横向放置,也可使用竖直放置。在七彩虹的控制中心iGameCenter中,可以对这块屏幕进行细致的自定义。支持显示CPU/GPU工作情况,也可以显示时间等内容,除此之外,这一屏幕也支持放置静态的图片、放置GIF图片进行显示。


另外七彩虹iGame GeForce RTX 4080 火神上配备的智屏也支持通过外置延长线和底座单独摆放,成为“桌面美学”的一部分。

如果不喜欢方方正正的智屏,七彩虹也贴心的准备了另一块RGB灯光组件,同样采用磁吸设计,放在显卡顶部后即可见到各式各样的灯效。不过有一点,这个灯控组件不兼容底座。


总的来说,七彩虹iGame GeForce RTX 4080 火神上的智屏给千篇一律的显卡设计带来了不一样的玩法,不过七彩虹或许可以考虑进一步升级智屏,使其可以显示歌词或者增加触屏操作等功能,让这块智屏更懂交互,更具可玩性。
2七彩虹iGame RTX 4080 Vulcan OC显卡拆解
显卡拆解:七彩虹iGame GeFore RTX 4080 16GB Vulcan OC
精致的外表下是扎实的堆料设计,卸下背板上的螺丝,断开风扇与智屏的接针后即可分离PCB与硕大的散热器。


拆下后可以看到七彩虹iGame GeForce RTX 4080 火神除了采用金属背板来对显卡PCB进行支持以外,还加入了金属中框,可以对于PCB进行更强的支撑,并且具备有辅助散热的效果。

再卸下金属中框上的螺丝即可完全分离PCB,PCB采用的是类公版的方案,越肩设计,比一般的显卡都要再高一些,不过PCB上的接口、供电、核心、显存,以及辅助供电位置都相当的合理且规正,有大厂出品的质感。

PCB的背板相比正面更为简洁,元器件更少,核心背部电容位置使用了两个POSCAP(导电聚合物钽电容),电气性能更强一些。

PCB正中央的AD103-300-A1核心便是此次的主角,采用TSMC4N工艺制造,拥有9728个CUDA核心,在游戏性能上可以达到RTX3080Ti的两倍,甚至部分场景下还能超越上代卡皇RTX3090Ti。

核心四周是8颗GDDR6X显存,颗粒来自美光,型号是型号为2PU47D8BZF,单颗显存容量2GB,8颗组成16GB,显存位宽为256Bit,速度达到了21Gbps。

七彩虹iGame GeForce RTX 4080 火神采用22+4相供电配置,其中核心供电为22相,显存供电为4相,供电位置被安排在PCB的两侧,这个供电规格比部分RTX4090还要豪华了。


每相供电都采用了独立的DrMos芯片,封装型号为BLN3,实际应为AOS的AOZ5311NQI-03,持续输出电流为55A。


供电控制芯片采用了三颗,分布在PCB的正反面,分别是:uP9512U、uP9521R,以及uS5650Q。其中uP9512与uP9521共同管理核心供电,可以做精细化的供电管理,而uS5650Q则是主要负责显存供电部分。



PCB的正反面各有一颗BIOS控制芯片,分别控制Normal模式和Turbo模式,型号为IS25WP016。


在PCB的右上角可以看到全新的12VHPWR供电接口,相比以往的8Pin接口,占用的地方要少很多,附近是两颗封闭电感用于保证RTX4080的供电稳定。

豪华的堆料自然要豪华的散热加持才能发挥全部战力,接下来看看七彩虹iGame GeForce RTX 4080 火神上全新的旋涡(Vortex)散热装置。这代旋涡(Vortex)散热装置可以分为三个部分,分别是散热风扇、散热器以及散热金属中框。

这一代的七彩虹iGame GeForce RTX 4080 火神的散热器本体相当庞大,不仅能够给GPU散热,还为显存、电感以及MOS管等进行散热。

在显存和供电部分都配上了高系数的导热垫辅助散热,GPU核心也抹上了厚厚的硅脂,显存位置更是紧贴真空腔均热板,超高的散热效能助力这一代显卡强劲的性能释放。

散热器本体为两段式散热模块,应用导流型鳍片,该设计最早用于高单价的服务器中,如今用于显卡上,为玩家提供更优的导热效果,并且采用弯角造型,进一步增大了鳍片与空气的接触面积。

散热器底下是9根8mm“回流焊”工艺热管,贯穿整个散热器,显然这是为超频而准备的。


散热器内部用的还是真空冰片技术,超扁平的密闭腔体内充冷凝液,吸收热量后通过相变原理散发热量,真空密闭腔体与热管及鳍片合为整体,散热效能突飞猛进。如此规格的散热系统前所未见,配合金属背板上的镂空设计,压这颗AD-103核心绰绰有余。
散热器上还有三个104mm的大直径风扇作为主动散热,直接固定在散热器上,与导流型鳍片直触,能够更好的排出内部热量。
升级的“聚风镰环”扇叶和双滚珠轴承为旋涡散热的关键,既保证了风量的充足又兼顾了风扇的寿命。
3测试平台&理论/游戏性能测试
测试平台介绍
七彩虹iGame GeForce RTX 4080 火神无论是供电、散热还是个性化设计都达到了旗舰级的水准,显然很对发烧玩家的胃口,接下来就进入大家最为关注的实战测试部分吧!
测试前先介绍一下本次的测试平台,CPU使用的是目前的旗舰——Inteli9-13900K处理器,主板为华硕Z790HERO,搭配金士顿的64GBDDR5-6000高规格内存,确保这张显卡能够释放全部性能。
七彩虹iGame GeForce RTX 4080 火神有着强劲的性能,配它的显示器自然也不能弱,用的依旧是天花板级别的AGONPD32M保时捷联名款,4K@144Hz的高刷,更有4080加持,通杀市面上的游戏。
测试前,首先用GPU-Z对显卡的运行状态以规格参数进行再次的检查,避免因为运行状态及参数不正确而导致测试成绩不正确。同时也能通过GPU-Z所呈现的数据来看看七彩虹iGame GeForce RTX 4080 火神显卡更为详细的规格参数。
从图上可以看到这张七彩虹iGame GeForce RTX 4080 火神显卡拥有9728个CUDA,Boost频率在TurboBIOS下就达到了2640MHz,相比公版的2505MHz有一定的提升。另外我们也全程开启主板的ResizableBAR功能,确保显卡性能满血释放。
理论性能测试
国际惯例,先跑一遍3DMark测试,从理论性能来看,七彩虹iGame GeForce RTX 4080 火神有着比上代RTX3080Ti更为出色的性能表现,整体性能是后者的1.3倍以上。尤其是在光线追踪以及DLSS项目上,七彩虹iGame GeForce RTX 4080 火神提升最为明显,基本能达到上代显卡的1.4倍以上。
而在注重游戏的TimeSpy和FireStrike测试中,七彩虹iGame GeForce RTX 4080 火神也有不俗的表现,虽然没有实现翻倍的性能提升,但性能至少是RTX3080Ti的1.4倍,只能说这次AdaLovelace架构与TSMC4N工艺的配合着实给我们带来了更多的惊喜。
而来到算力方面,我们使用AIDA64GPGPU进行测试,虽然RTX4080的显存位宽不及RTX3080Ti,但其算力丝毫不弱,显存复制能力是RTX3080Ti的2.6倍之多,算力也有近1.4倍的提升,还好现在以太坊已经合并了,不然这显卡又会是空气卡了。
游戏性能测试
看完了理论性能测试,RTX4080的提升着实让人眼前一亮,那这张核弹级的显卡在游戏中究竟表现如何呢,我们选取了多款游戏进行实测。
在1080P分辨率下,由于显卡压力不大,所以常规的游戏性能提升其实不算明显,不过开启DLSS后,游戏性能小幅提升,像跑分界的活化石《古墓丽影:暗影》,七彩虹iGame GeForce RTX 4080 火神开启DLSS后,帧数达到了309。
2K分辨率下,七彩虹iGame GeForce RTX 4080 火神逐渐与前代拉开差距,市面上的大部分3A游戏都能稳定120FPS以上运行,部分游戏甚至奔着200+FPS而去。
七彩虹iGame GeForce RTX 4080 火神在4K分辨率下也同样游刃有余,超高画质下依旧可以流畅运行绝大部分的游戏,像显卡杀手《赛博朋克2077》,这张显卡能够在超级光追的画质下跑出接近80帧的成绩,而RTX3080Ti甚至没有60FPS。部分游戏还可以飙到140FPS左右,4K144Hz电竞不再是梦。
即使分辨率上到8K,七彩虹iGame GeForce RTX 4080 火神也丝毫不虚,性能是前代的1.4倍,开启DLSS后依旧能够将大部分游戏跑到60FPS以上的水准,像一些优化较好的游戏,例如《极限竞速:地平线5》甚至能有70FPS左右的帧率,8K在墨西哥的赛道上狂飙看风景,这在之前可是想都不敢想。
另外值得一提的是七彩虹的控制中心iGameCenter中配有游戏监控功能,能够开启监控游戏性能,给玩家更直观的数据,方便及时调整显卡状态,以获得更强劲的性能输出。
并且已有30多款游戏支持记录游戏日志功能,能够更详细的了解游戏运行状态。
4DLSS 3性能测试
DLSS 3性能测试
老黄在发布会上带来了DLSS3技术,这个技术相比DLSS2新增了帧生成和NVIDIAReflex,在RTX40系列显卡上能实现成倍提升性能,帧数进一步提升的同时,还不会影响画质和响应速度,有了这项技术,4K144甚至8K60不再是梦。
并且DLSS3游戏支持发展迅速,截至11月15日,已有10款可玩的DLSS3游戏发布。
《瘟疫传说:安魂曲》(APlagueTale:Requiem)
《光明记忆:无限》(BrightMemory:Infinite)
《毁灭全人类2:重新探测》(DestroyAllHumans!2-Reprobed)
《暗影火炬城》(F.I.S.T.:ForgedinShadowTorch)
F1®22
《逆水寒》(Justice)
《生死轮回》(Loopmancer)
《漫威蜘蛛侠:重制版》(Marvel’sSpider-ManRemastered)
《微软模拟飞行》(MicrosoftFlightSimulator)
《超级人类》(SUPERPEOPLE)
另外像WRCGenerations,《极品飞车:不羁》(NeedforSpeedUnbound)以及《战锤40K:暗潮》(Warhammer40,000:Darktide)也即将发布,圣诞节前玩家就可畅玩这些DLSS3游戏。想要了解更多DLSS3的信息可以关注下面的链接(北京时间11月15日22:00上线)。
https://m.nvidia.com/en-us/geforce/news/more-november-2022-rtx-dlss-game-updates
3DMarkDLSS3性能测试
讲完DLSS3的进展,下面就该上实测了,在3DMark的DLSS3测试中,七彩虹iGame GeForce RTX 4080 火神开启DLSS3后性能提升十分明显,3DMARKDLSS3开4K测试,能够跑到147FPS,可以说能够完全满足4K@144。甚至于在8K分辨率下也能满足60FPS流畅运行,似乎已经可以期待下8K@120了。
《生死轮回》(Loopmancer)游戏实测
单看理论测试可不够,在《生死轮回》游戏中我们也实测了DLSS2与DLSS3的游戏性能,在不开启DLSS的情况下,七彩虹iGame GeForce RTX 4080 火神在4K分辨率下运行《生死轮回》仅有50FPS;开启DLSS2后,游戏帧数可以去到122FPS,1%帧数也达到了74FPS,基本可以满足4K60的游戏需求。
在开启DLSS3之后,事情就变得有趣了,游戏性能肉眼可见的提升,帧数更是达到了143FPS,配上顶级的4K@144显示器,例如我们测试中使用的AGONPD32M,玩此款游戏那是真爽了。
UnrealEngine5EnemiesDEMO
我们也测试了用最新UnrealEngine5引擎制作的EnemiesDEMO,Enemies是NVIDIA提供给媒体与各大KOL测试所用的DEMO,利用UnrealEngine5轻松制作了一个数字人类。这里大家可以直接对比下开启和关闭DLSS3前后的画面和FPS值,4K分辨率下七彩虹iGame GeForce RTX 4080 火神可达77AVG/661%FPS/55ms的水平,而关闭DLSS3后仅有22AVG/171%FPS/195ms,基本就是3.5倍的游戏流畅度提升。
2K分辨率与4K分辨率DLSS性能测试
DLSS3的性能测试我们这里做了两个分辨率与十个项目,这里就不再单一的说了,笔者弄个汇总的表格给大家作参考之用吧。注意:DEMO里是没帧生成开关的,所以30系列显卡其实运行在DLSS2模式之下。
总的来说,七彩虹iGame GeForce RTX 4080 火神即使是开启DLSS2,性能已经比前代的RTX3080Ti强出不少,如果是开启DLSS3后,那帧数提升更为明显,2K@180甚至4K@144都轻轻松松,只能说老黄给40系显卡上DLSS3有一手,一下子就跟30系显卡拉开了差距。
另外我们也用七彩虹iGame GeForce RTX 4080 火神测试了8KDLSS3游戏的性能表现,但是遇到了爆显存的情况,主要表现为显存占用达到了16GB,游戏帧数也较低。只能说老黄的刀法是真精准,目前只能等游戏厂商优化,如果能够降低更少的显存占用,那RTX4080体验8K60是完全没问题的。
5创作者能力测试
创作者性能测试
游戏性能的提升大家有目共睹,那这块七彩虹iGame GeForce RTX 4080 火神用在内容创作上究竟如何,我们分为视频内容生产力以及专业内容创作两个部分进行测试。视频生产力方面,先看PCMark10的测试结果,七彩虹iGame GeForce RTX 4080 火神在生产力与游戏两个子项中提升会猛一些,领先RTX3080Ti约13%。
而在Adobe、DaVinci等软件中,得益于全新的AV1编码和RTX4080双Buff加成后,性能均有所提升,如果你是一名想要追求更高效率的设计师、后期小哥等,不妨试试七彩虹iGame GeForce RTX 4080 火神,它能带给你不一样的创作体验。
如果你是专注于渲染或工业领域的应用,RTX4080能给你带来更大的惊喜,在SPEC工业软件测试里,新架构、大显存的加持下,性能是RTX3080Ti的1.3倍;而在Blender或OCtanebench渲染中,RTX4080的提升更猛,是前代的1.5倍之多,对于专业领域的用户来说,升级这张七彩虹iGame GeForce RTX 4080 火神真是太有必要了,能提高不少工作效率。
而说到创作性能就不得不提RTX40系最大的升级——这一代的RTX4080提供了NVENC双编码器,既支持AV1编码也支持AV1解码,AV1相比H.265能够以更低带宽、更小文件提供更高质量的画质,并且完全开放没有任何授权费用,正陆续得到更多平台、软件的支持。
所以我们也对第8代NVENC双编码器进行测试,测试片源来自NVIDIA提供的8K片源与工程文件,七彩虹iGame GeForce RTX 4080 火神的导出速度堪比RTX4090,尤其是8K30规格的视频用时甚至更短一些。而即便是相同的H.265格式,七彩虹iGame GeForce RTX 4080 火神的导出速度是前代RTX3080Ti的2.6倍。
在MAGICMASK工程文件的测试与ON1Resize的项目测试中也表明,七彩虹iGame GeForce RTX 4080 火神内置的第8代NVENC双编码器很强大,而且利用RTX40核心里的黑技术,可以让渲染的时候更短,大大的加快效率。
我们再来看看H.265格式与AV1格式下的画质区别,从肉眼来看,其实画质几乎完全一样,这样也意味着AV1可以用更小的空间占用量实现与H.265同等规格的画质表现,总的来说,无论是导出速度、空间占用还是画质表现,它都完胜H.265。
6超频&功耗&总结
功耗与发热
相信大家已经见识过RTX4090的功耗与散热了,那采用同款散热器的七彩虹iGame GeForce RTX 4080 火神在功耗与散热上是否能带来更多惊喜,我们利用Furmark软件,来对这块七彩虹iGame GeForce RTX 4080 火神的功耗和散热表现进行测试。
在室温25°的环境下,Furmark甜甜圈设定为1280x720分辨率。在烤机15分钟后,TURBOBIOS下的显卡占用率达到了100%,满载功耗379.152W,显卡运行频率顶着2700MHz在跑,核心满载温度稳定在62.5℃,显存满载温度为54℃,甚至比公版2505MHz下还要低上不少。
而在Normal模式下,这块显卡要冻感冒了,显卡核心频率为2445MHz,核心满载温度稳定在57.3℃,显存满载温度为54℃,功耗也只有300W出头,有了TSMC4N工艺的加持,相比上一代的RTX3080Ti,功耗温度双双表现出色,并且风扇噪音明显降低了不少,喜欢安静的用户不妨试试这个模式。
我们也横向对比了一下上代显卡与RTX 4090显卡的功耗,从功耗来看,其实七彩虹IGame GeForce RTX 4080火神的功耗控制还是相当不错的,最高才是300W还比RTX 3080 Ti少多了,而且性能更强了。
测试的时候其实我们同时利用HWINFO64在后台进行功耗记录,结果如上图一样,RTX 3080 Ti基本跑的是350W,而七彩虹iGame GeForce RTX 4080火神也就300W左右,部分应用软件上甚至更低的功耗表现。所以说RTX 4080 16GB每瓦性能比是实打实的提升到了一个新高度。
超频测试
因为这一张七彩虹iGame GeForce RTX 4080 火神的散热规格本身也足够强大,官方配套的iGameCenter控制软件也自带有非常方便的超频设置,笔者自然是不能错过这个绝佳的超频机会。
虽然七彩虹iGame GeForce RTX 4080 火神在Turbo BIOS下的BOOST频率已经到2640MHz了,但还有超频空间,所以我们使用iGameCenter的超频设置,对这张显卡进行超频,简单小超一下后,测试时GPU核心频率最高可以到2985MHz,此时跑3DMark的PortRoyal光追测试,显卡得分18062,相比默认状态下的17599有了小幅提升。
就差临门一脚就冲上3000MHz了,那不得继续超一下,所以我们继续超频,将显卡的核心频率超至2775MHz,超频后3DMark的PortRoyal光追测试显卡得分18158,GPU核心频率直接来到了3015MHz,这在以前是想都不敢想的,已经接近部分CPU的频率了。
笔者也在超频状态下,对七彩虹iGame GeForce RTX 4080 火神进行了烤机测试,核心频率基本维持在2895MHz,显存频率为1400MHz,本以为超频后温度会大幅提升,但七彩虹的旋涡(Vortex)散热装置很给力,显卡核心温度稳定在59℃左右,不得不说这一张显卡的散热性能确实可以,超频后的温度表现也依然很优秀,此时的烤机功耗在429W左右。
评测总结
全新AdaLovelace架构的RTX40系显卡无论是在游戏性能还是专业生产力上都带来了质的飞跃,RTX4080的性能足以让游戏玩家为之发狂,4K光追丝滑流畅;创作者也为其痴迷,大显存、高性能为提升效率助力,可以说这一代RTX40系显卡从里到位都是惊喜。
聊回本次的主角——七彩虹iGame GeForce RTX 4080 16GB Vulcan OC,对于追求极致游戏体验的发烧玩家和追求顶级效率的设计师用户来讲,七彩虹iGame GeForce RTX 4080 16GB Vulcan OC毫无疑问是性能与性价比的最优选,在堆料方面有着超越公版的配置,用料豪华,散热强劲,在超频方面颇有潜力,轻轻松松3GHz,完美诠释了旗舰级显卡应有的水准。
在个性化上,这代七彩虹iGame GeForce RTX 4080 16GB Vulcan OC加入的智屏也让显卡有了更多的可玩性、交互性,这让它在同质化严重的显卡市场脱颖而出,毕竟各大非公显卡的频率、性能、散热设计等日渐趋同,只有这种差异化设计才能俘获玩家的芳心。
总的来说,七彩虹iGame GeForce RTX 4080 16GB Vulcan OC显卡称得上是给追求性价比与高性能用户量身定做的完美之作,目前七彩虹iGame GeForce RTX 4080 16GB Vulcan OC已经上市,感兴趣的玩家不要错过,如果你想现在入手一张高端显卡,它就是你一步到位的选择。
另外11月16号晚10点,七彩虹将在京东、天猫、抖音、快手等电商平台及线下授权零售经销渠道正式以现货发售或预售的形式同时上架多款iGame、战斧GeForce RTX 4080显卡包含 iGame GeForce RTX 4080 16GB Vulcan OC、 iGame GeForce RTX 4080 16GB Neptune OC、 iGame GeForce RTX 4080 16GB Advanced OC、iGame GeForce RTX 4080 16GB Ultra OC及战斧GeForce RTX 4080 16GB 豪华版,感兴趣的话可以去了解一下。
7ADA架构讲解
Ada Lovelace架构讲解
Turing、Ampere上两代架构核心均以人物来命名,前者是计算机科学之父——艾伦·麦席森·图灵;后者则是“电学中的牛顿”——安德烈·玛丽·安培,电流的国际单位安培就是以其姓氏命名。那AdaLovelace定非凡人,度娘一下果然,这是 人称“数字女王”的阿达·洛芙莱斯,编写了历史上首款电脑程序,是被世界公认的第一位计算机程序员,果真是一代比一代还要更牛。PS:她的父亲是《唐璜》的作者,诗人拜伦喔。
从Turing架构开始,NVIDIA首次在显卡中加入了加速光线追踪的RTCore单元,以及面向AI推理的TensorCore单元,这革命性的创新使实时光线追踪成为可能。而Ampere架构则是全面的架构改进,在加入新一代的二代RTCore和三代TensorCore基础上,还有着更先进的SM单元设计,这样显卡工作效率那是翻倍的提升。而来到AdaLovelace架构,同时是以效率提升为大前提,自然是引入了最新的第三代RTCores与第四代TensorCores单元,同时加入众多新颖的黑科技,从执行效率来说AdaLovelace架构是上代Ampere架构的2倍以上,甚至光线追踪能力更是达到了恐怖的4倍性能。
全新的SM流式多处理器
AdaLovelace架构中最大的亮点之一:全新的SM流式多处理器,每个SM包含了128个CUDA核心、1个第三代的RTCores,4个第四代TensorCores(张量核心)、4个TextureUnits(纹理单元)、256KBRegisterFile(寄存器堆),以及128KBL1数据缓存/共享内存子系统,于是这一个全新的SM单元有着超过上一代2倍之的性能表现。
过去的Turing架构INT32计算单元与FP32数量是一致的,而两者相加才组成了64个CUDA核心。但是Ampere架构开始,左侧的计算单元实现了FP32+INT32的计算单元并发执行,也就是说CUDA核心数量翻倍到了128个。
再来看看AdaLovelace架构的SM,FP32/INT32的计算单元组合,同样实现了每个SM内含128个CUDA的设计,看似提升不大,但是当你了解到GeForceRTX4080拥有76个SM,9728个CUDA核心,那你也就应该明白达82.6TFLOPS的着色器能力是如何实现的了,比上一代的RTX3090Ti显卡的40TFLOPS,还真是提升了两倍有多。
另外缓存方面AdaLovelace架构也进行了大规格的提升,首先每个SM单元中单独配上了128KB的缓存,这样RTX4080显卡中就实现了97MBL1/共享内存。其次核心的二级缓存进行进行了重新的设计,并且完整AD103核心与RTX4080都是64MB二级缓存,相比RTX3080Ti可以说是质的飞跃。
技术讲解:第三代RTCores与第四代TensorCores
以为刚才的CUDA数量与超大L2缓存就已经很猛了,实现上AdaLovelace架构最大的提升还是在第三代RTCores与第四代TensorCores身上。
第三代RTCores
RTCores用于光线追踪加速,第三代RTCores的有效光线追踪计算能力达到191TFLOPS,是上一代产品2.8倍。
在Ampere架构中,第二代RTCores支持边界交叉测试(BoxIntersectiontesting)和三角形交叉测试(TriangleIntersectiontesting)。用于加速BVH遍历和执行射线三角交叉测试计算,虽然光线追踪处理能力已经比初代的Turing架构核心更高效,但是随着环境和物体的几何复杂性持续增加,传统的处理方式很难再以更高效率、正确反应出的现实世界中的光线,尤其是光的运动准确性。
所以在第三代RTCores增加了两个重要硬件单元:OpacityMicromapEngine与DisplacedMicro-MeshesEngine引擎。OpacityMicromapEngine,主要是用于alpha通道的加速,可以将alpha测试几何体的光线追踪速度提高2倍。
在传统光栅渲染中,开发人员使用一些Alpha通道的素材来实现更高效的画面渲染,例如Alpha通道的叶子或火焰等复杂形状的物体。但在光线追踪时代,这传统的做法会为光线追踪带为不少无效的计算,例如运动性的光线多次通过一块叶子,光线每击中一次叶子,都会调用一次着色器来确定如何处理相交,这时就会做成严重的执行成本与时间等待成本。
而OpacityMicromapEngine用于直接解析具有非不透明度光线交集的不透明度状态
三角形。根据Alpha通道的不透明,透明与未知等三个不同的块状态进行处理:透明则直接忽略继续找下一个,不透明块则记录并告之命中,而未知的则交给着色器来确定如何处理,这样GPU很大部分都不需要进行着色器的调试处理,能够实现更为高效的性能。
DisplacedMicro-MeshesEngine
如果说OpacityMicromapEngine加速的是面处理,那么DisplacedMicro-MeshesEngine就是几何曲面细节的加速器。如上图所示,在AdaLovelace架构中,通过1个基底三角形+位移地图,就可以创建出一个高度详细的几何网格,所需要资源占用比二代RTCores更低,效率也更高。
通过NVIDIA给出的创建14:1珊瑚蟹例子来说事,这里我们需要需要1.7万个微网格、160万个微三角形,在AdaLovelace架构中BVH创建速度可加快7.6倍,存储空间缩小8.1倍。DisplacedMicro-MeshesEngine起到了关键性的作用,其将一个几何物体根据不同细节分成密度不一的微网络处理,红色密度超高,细节处理越为复杂。相应的低密度微网络区域则可以释放更多的资源与存储空间,这样DisplacedMicro-MeshesEngine就可以帮助BVH加速过程,减少构建时间和存储成本。
同时AdaLovelace架构SM中新增了着色器执行重排序(ShaderExecutionReordering,SER),这是由于光线追踪不再只有强光或者阴影渲染处理,未来将会更多的是在光线的运动性,这样光线就会变得越来越复杂,想要第三代RTCores与第四代TensorCores有着更高的执行效率,那就得为他们来安排一位管家。而着色器执行重排序(SER)就是为了能够即时重新安排着色器负载来提高执行效率,为光线追踪提供2倍的加速,也能更好地利用GPU资源。不过目前仍未有实例,想实现这个功能,还得游戏与开发工具的支持才行。
第四代TensorCores
TensorCores是专门为执行张量/矩阵运算而设计的专用执行单元,这些运算是深度学习中使用的核心计算功能。第四代TensorCores新增FP8引擎,具有高达1.32petaflops的张量处理性能,超过上一代的5倍。
8DLSS 3技术讲解&双编码器
技术讲解:DLSS 3
或者说第四代TensorCores太硬核你不会知道是啥?提升意义在哪?但是TensorCores最经典的应用DLSS你肯定会知道,这一次AdaLovelace架构支持NVIDIA最新的DLSS3技术。
https://images.nvidia.cn/cn/youtube-replicates/r-hu006p23I.mp4
之前我们也聊过DLSS技术,其设计之初是为了弥补光线追踪技术后的性能损失,具体的表现为开启光线追踪技术后游戏帧数大幅度的下降,甚至很难保证游戏流畅的运行。于是DLSS使用低分辨率内容作为输入并运用AI技术输出高分辨率帧,从而提升光线追踪的性能。
在DLSS3中包含了三项技术:DLSS帧生成、DLSS超分辨率(也称为DLSS2)和NVIDIAReflex。你可以理解为DLSS3是在DLSS2的基础上,新增了DLSS帧生成技术;而后两技术中,DLSS超分辨率只需要GeForceRTX显卡都能使用上,NVIDIAReflex则是GeForce900系列以后的显卡都用使用上。
想实现DLSS帧生成可不简单,这需要配合上AdaLovelace架构的GeForceRTX40系列显卡才行。DLSS帧生成技术原理是:利用AI技术生成更多帧,以此提升性能。DLSS会借助GeForceRTX40系列GPU所搭载的全新光流加速器分析连续帧和运动数据,进而创建其他高质量帧,同时不会影响图像质量和响应速度。
从Ampere架构开始,NVIDIA显卡就已经支持了光流加速器,而AdaLovelace架构的光流加速器升级到了第二代,其提供了高达300TeraOPS(TOPS),比安培架构的初代光流加速器(OpticalFlowAcceleration,OFA)快2倍以上。为了实现DLSS帧生成,OFA扮演了重要的角色,其配合上新的运行矢量分析算法在DLSS3技术框架内实现精确和高性能的帧生成能力。
另外,由于DLSS帧生成是在GPU上作为后处理执行的,那么即使在游戏受到CPU性能限制的时候,我们同样能够从中获得更好的游戏性能提升。尤其是那种物理计算密集型的游戏或大型场景游戏,DLSS2均可以让GeForceRTX40系列显卡以高达两倍于CPU可计算的性能来渲染游戏。
最后由于DLSS3是建立在DLSS2基础之上的,游戏开发者可以在已支持DLSS2或NVIDIAStreamline的现有游戏中快速集成该功能,所以DLSS3已在游戏生态得到广泛应用,目前已有超过35款游戏和应用即将支持该技术。
阅读小亮点:NVIDIAReflex
NVIDIAReflex也是DLSS3其中的一环,它可以使GPU和CPU同步,确保最佳响应速度和低系统延迟。
想要实现端对端的最低延迟,你需要确保游戏、显示器以及鼠标三者都同时支持并开启了Reflex技术。
当GeForceRTX40系列显卡和NVIDIAReflex搭配上后,直接达到1440p分辨率360FPS的体验,这着实是性能有点强劲了。
在GTC2022大会时已经透露将会还有4款1440p分辨率的新型G-SYNC电竞显示器将要发布,包括采用mini-LED技术的AOCAG274QGM–AGONPROMiniLED、MSIMEG271QMiniLED和ViewSonicXG272G-2KMiniLED三款显示器刷新率均为300Hz,而最猛的是ASUSROGSwift360HzPG27AQN,刷新率直接来到了360Hz。
但唯一一个问题就在于,部分显示器厂商认为此类产品受众人群较少,会降低此类显示器的产能,甚至产品就已经被内部PASS掉,所以1440p360Hz是很美好,但现实也是相当的骨感。
技术讲解:双NIVDIA编码器(NVENC)
GeForceRTX40系列显卡还有一个全新的升级,那就是双编码器NVENC。第八代的NVENC双编码器不仅支持H.264与H.265,还支持开放式视频编码格式AV1。
而由于AV1是一种免版税的视频编码格式,上游软件厂商与下游戏的配套端都在大力推广此编码格式,我们也会看到越来越多的硬件与软件支持AV1格式,包括剪映专业版、DaVinciResolve、以及AdobePremierePro较为流行的Voukoder插件均支持,且均可通过编码预设使用双编码器,这样我们等待视频导出的时间缩短将近一半。
不单是视频制作软件,AV1格式也将会是主播、游戏直播UP主们的新宠儿,在保证画面最高质量的情况下,AV1编码器可将效率提高40%,同时显卡的占用也更低。包括OBSStudio一一代软件中也会增加AV1格式的支持。另外我们还能通过GeForceExperience和OBSStudio录制高达8K60的内容,这样我们做游戏录制也会变得更为轻松。
包括我们之后测试时使用的游戏内录视频都是支持AV1格式,同时双编码器NVENC在资源占用和适配上做得越来越好。