像盖楼一样构建CPU,AMD怎么做到的?探究其制造工艺
今天跟大家一起来学习下CPU架构的演进过程。
在CPU市场,Intel和AMD可以说是一对老对手了(虽然Intel可能瞧不上AMD)。

在2000年代中期,AMD采用低IPC和低效率的设计组合,结果在与Intel竞争中大败,被Intel按在地上摩擦再摩擦。
这个状态持续了近十年。直到2017年,随着Zen微体系结构的到来,才让AMD卷土重来。那么到底Zen架构发生了哪些变化,导致了这种转变?

▉ 01 为什么我们需要架构升级?
首先,让我们掀起CPU上面那个金属盖头,看看这个小小CPU的内部世界。

绿色的是基板(substrate),可以看作是一个小小的电路板;正中的是CPU的核心--Die,里面有内核、控制期和其它功能模块,整个CPU我们统称之为 Package。
为了方便更好的理解文章的内容,我们将CPU比喻成一栋大楼,基板就相当于地基,Die就相当于大楼主体设计,里面的内核、控制期就相当于大楼里的每个小房间,数据流和指令流就相当于串门的通道。
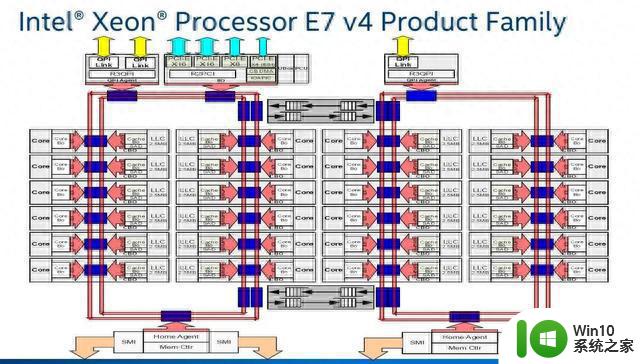
Intel的Pakcage内部是一个Die, Core之间原来是Ring Bus,在Skylake后改为Mesh。
这种CPU设计方式一直是Intel采用的架构设计模式,是典型的大核设计(monolithic die),它只有一个Die,所有重要电路、功能版块都在Die里面。
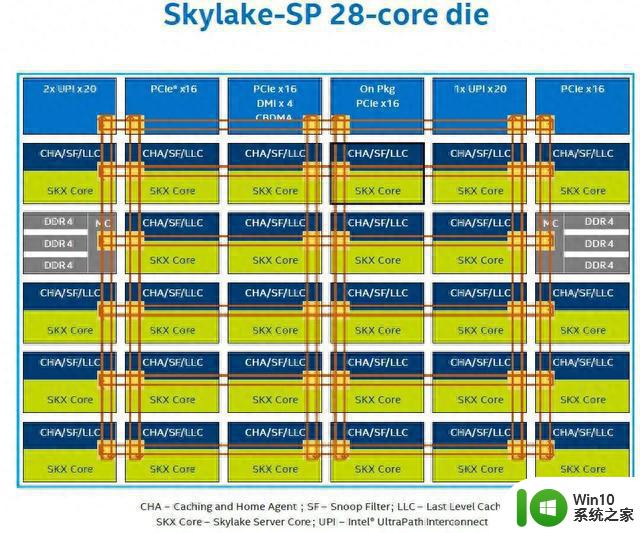
这种方式就跟我们现在的商品楼的建设方式很像,它带来的好处就是,内部线路众多,统一调度,可以很方便大家串门,所以性能好,延迟低,所以处理事情快。
这种设计方式在工艺发展到一个程度后有一个缺点,就是大楼整体的尺寸有限制,并不是无限制的增高增大。如果需要构建更多的房间,那么Die里就需要加入更多的内核,只能让建筑工艺不断的提升。
但制作工艺也有个极限,当Intel工艺达到14nm的时候被卡了很久。制作工艺不断复杂的情况下,直接影响Die的良率,导致成本越来越高,因此处理器性能提升缓慢。
当到了10nm和7nm的时候,新型器件的结构导致工艺更加复杂,单独大核的设计方式已经很难提升CPU的性能,摩尔定律面临失效。
面对这个挑战,AMD率先求变,对CPU设计方法进行了重新构想。
面对建设高楼越来越难的问题,AMD放弃了搞单个大高楼的打算,而是在原地建了4个小楼,再把小楼连接起来,这样房间数量不变,还解决了高层难建的问题。

AMD EPYC服务器芯片
这种做法被叫做Chiplet方案,也有叫MCM (Multi-Chip-Module,可以看做初级版Chiplet),但这种方式的缺点就是4个下楼之间的连接是个问题,会大大影响CPU的延迟。

AMD第一代Ryzen的延迟最明显。后来,AMD利用 Infinity Fabric技术,从而显着提高了CPU性能。

由于采用Infinity Fabric链接一般会做到基板上,使得Package更像一个小型的主板。我们来看一下透视照,可以看到布线密密麻麻,这也导致地基上很难建更多个小楼,因此每个Package限制了集成IP的个数。
▉ 02 Chiplets的架构设计和分类
通过Chiplet技术,AMD可以在单个基板上集成更多的核心数,使用10nm工艺制造出来的新品,完全可以达到7nm大核心芯片的集成度。同时Chiplet在研发成本和一次性生产投入要少的多,Chiplet让AMD在市场上打了一个翻身仗。

由于高集成度低成本等优势,Chiplet在市场上迅速得到了越来越多厂商的跟进。Intel、华为、苹果以及国内很多厂商厂商都陆续推出Chiplets芯片。目前来看,主流的Chiplets设计思路根据Chiplets的功能划分可以分为两类:
第一类,
以AMD Zen2/3/4架构、Huawei Lego(Kunpeng&Ascend)为代表,这类厂商将功能划分到多个Chiplets,单个Chiplet不包含完整的功能,通过不同Chiplets组合封装来实现不同类型的产品。
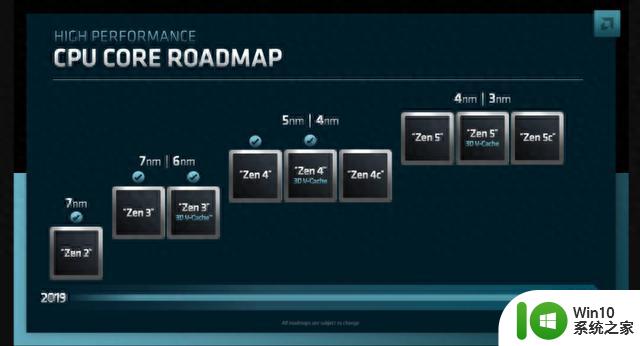
比如AMD Zen4架构,采用CCD(compute)和CIOD(memory interface + I/O)组合的形式进行不同Chiplets功能拆解。AMD EPYC 9004就是采用12个CDD+1个IO Die的方式,每个CDD包含12个核心,从而让9004达到了96核心的设计。
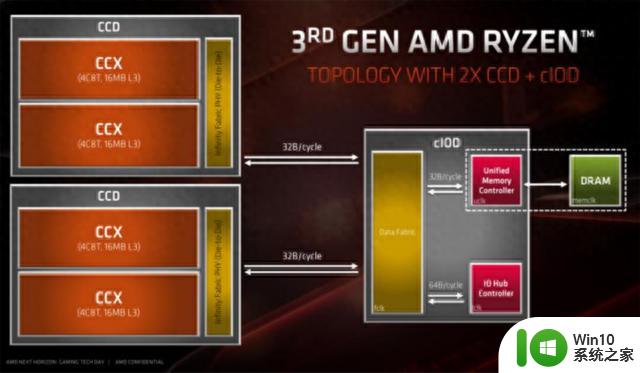
AMD利用这种设计架构获得顶级的 算力和能效,在面积与先进工艺差别不大的情况下获得成本收益。并且CCD本身按照两个4C8T cluster组合的形式设计,可以适应AMD从Desktop到Server的架构需求,根据场景选择CCD数量和设计对应的CIOD即可,灵活度非常高。
另外,Huawei Lego架构采用的是compute die(compute + memory interface)和I/O die组合的形式,不同的Chiplets的数量和组合形式都可以灵活搭配,从而组合出多种不同规格的云端高性能处理器产品。
第二类
以Intel Sapphire Rapids、Apple M1 Ultra为典型代表,单个Chiplet包含较为独立完整的功能集合,通过多个Chiplets级联获得性能的线性增长。

比如Intel Sapphire Rapids:通过两组镜像对称的相同架构的building blocks,组合4个Chiplets,获得4倍的性能和互联带宽。每个基本模块包含计算部分(CHA & LLC & Cores mesh, Accelerators)、memory interface部分(controller, Ch0/1)、I/O部分(UPI,PCIe)。
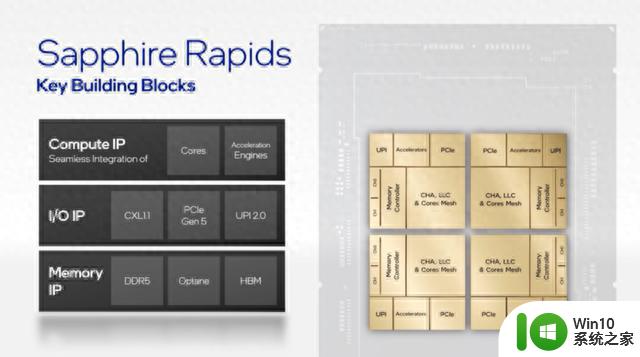
通过将上述高性能组件组成基本的building block,再通过EMIB技术进行Chiplet互联,可以获得线性性能提升和成本收益。
Apple M1 Ultra则是通过自研的封装技术UltraFusion来堆叠两颗M1 Max芯片,使得两颗芯片之间拥有超过2.5TB/s带宽且极低延时的互联能力。基于这个互联的延时带宽能力,可以使得M1 Ultra直接获得两倍M1 Max的算力,同时在软件层面依然可以将M1 Ultra当做一个完整芯片对待,而不会增加额外的软件修改和调试的负担。
▉ 03 Chiplet的架构设计面临的挑战
Chiplet技术改变了传统的技术演进方式。在某种程度上说,可以说是"产业链局部重塑"。但这种架构上的改变必然要面临新的挑战。

不仅要考虑多个Chiplets如何进行有效互联和扩展,保证新品的灵活扩展能力,还要避免多Chiplets之间出现信号死锁、流量拥塞等功能和性能问题。因此,Chiplet技术在芯片的封装、电路设计、通信协议等方面都面临着新的挑战。。
封装技术
先进封装技术是Chiplet实现的基础和前提,事实上也正是由于先进封装技术的突破才让Chiplet技术从构想走入现实。
目前,Chiplet封装技术目前主要由TSMC、ASE、Intel等公司来主导,包含从2D MCM到2.5D CoWoS、EMIB和3D Hybrid Bonding。本文主要介绍目前工业界主流的2D和2.5D封装技术和其优缺点。
1. MCM(Multi-Chip Module)
这个方式比较传统,技术比较简单粗暴。Die之间的通讯通过在基板内布置电路来解决。

这个技术由来已久,本身CPU设计就包括Package电路设计。这样设计的SOC形式的CPU比较多,也相对成熟,比较典型的是Intel将CPU和南桥集成到一个CPU Package的SOC和AMD的Threadripper和EPYC。MCM技术简单可靠,但缺点十分明显,由于集成密度很低,难以形成大规模连接从而限制了集成IP的个数。
2. CoWoS(Chip-on-Wafer-on-Substrate)
CoWoS通过在基底和Die之间加入一层硅中介层(silicon interposer)可以帮助我们解决传统MCM技术的低集成度弊病:一层薄薄的中介层被加入基底核Die之间,起到承上启下的作用。
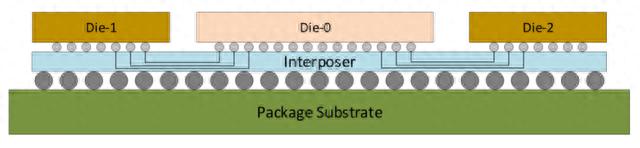
Die和Die之间的通讯可以通过中介层链接,从而提高Package的集成度。中介层目前有两种形式:一种是Passive interposer形式,2.5D封装,interposer里面只有电路。另一种是Active interposer形式,3D封装形式,interposer里面除了有电路还可以有其他器件。
但它也有自己的问题,硅中介质会增加Package厚度,interposer增加额外的成本,而且最重要的是,Die的所有连接必须全部通过interposer,大大增加CPU制作成本很工序。目前AMD走的就是这个方向。
3.EMIB(Embedded Multi-die Interconnect Bridge)
EMIB是Intel主导的2.5D封装技术,使用多个嵌入式包含多个路由层的桥接芯片,同时内嵌至封装基板,达到高效和高密度的封装。由于不再使用interposer作为中间介质,可以去掉原有连接至interposer所需要的TSVs,以及由于interposer尺寸所带来的封装尺寸的限制,可以获得更好的灵活性和更高的集成度。

总体而言,相比于前述介绍的MCM、CoWoS和InFO/LSI技术,EMIB技术要更为优雅和经济高效,获得更高的集成度和制造良率。但是EMIB需要封装工艺配合桥接芯片,技术门槛和复杂度较高。
通信协议
通信协议是保证不同Chiplet之间能够顺利的完成数据交互的必要保证,也是决定Chiplet能否"复用"的前提条件。

工业界大约从2016年开始就在逐步尝试基于Chiplet的芯片设计,经过长时间的摸索。已经在封装工艺、架构设计上有了深厚的积累和长足的进步,在这样的背景和契机之下,由Intel、AMD、ARM、ASE、Google、 Meta、Microsoft、Qualcomm、Samsung和TSMC共同开发和制定的UCIe 1.0在2022年3月正式推出。
UCIe标准的初衷和目标,是建立一套Chiplet技术相关的设计和制造等各个环节的参考标准,从而使得不同设计和制造厂商的芯片可以无缝集成,从而打造封装层级的完整灵活的芯片开发生态系统。
基于Chiplet技术和UCIe标准,可以实现超过单个掩膜版尺寸的芯片面积,获得更大尺寸、更高集成度的高性能芯片。同时基于标准的UCIe,可以使能各类不同工艺和不同大小的芯片和IP在封装层面进行集成,有效降低开发成本,同时减少开发周期。
▉ 04 总结:
从目前来看,由于摩尔定律(要求每两年将处理能力提高一倍)已经全面放慢了,单个处理器内核的速度不会每两年提高一倍。因此,提高性能的唯一方法就是扩展内核和堆叠内核。Chiplet技术已经逐渐走向成熟和商用,成为芯片厂商比较依赖的技术手段,也被认为是未来芯片行业发展的重要方向。