做完GPT-4完整测评,微软爆火论文称初版AGI就快来了
机器之心编辑部
GPT-4 的能力什么档次?
1956 年,在达特茅斯学院召开的一个研讨会上,人工智能这一概念正式被提出。
之后这个词一直挑战着心理学家、哲学家和计算机科学家,因为它太难被定义了。1994 年,52 名心理学家联合发文试图捕捉它的本质。
随着时间的推移,研究者开始将注意力转移到特定领域的 AI 系统,如 2016 年 AlphaGo 挑战韩国冠军棋手大获全胜。之后,时间来到 20 世纪 90 年代末和 21 世纪初,研究者不满足于专用 AI,因此开发更通用的人工智能系统呼声越来越高。随之而来的是,通用人工智能 (AGI) 一词开始在 2000 年代初期流行起来。
最近一段时间,如大家所见,大型语言模型 (LLM) 走到聚光灯下,这些神经网络基于 Transformer 架构,并在大量文本数据集上训练而成。尤其是 OpenAI 最新发布的 GPT-4,更是展示了大型语言模型的通用性,在数学、文字、法律、医学等领域样样精通。
我们不禁会问,GPT-4 是迈向 AGI 的重要一步吗?
微软给出的答案是肯定的,在其最近发布的一篇论文中,他们阐述了这个观点。文中对 GPT-4 进行了全面评测。微软认为「鉴于 GPT-4 能力的广度和深度,我们相信它应该被合理视作一个通用人工智能(AGI)系统的早期(但仍不完整)版本。」
微软还表示,「本文的主要目标是对 GPT-4 的能力和局限性进行探索,我们相信 GPT-4 的智能标志着计算机科学及其他领域的真正范式转变。」

论文地址:https://arxiv.org/pdf/2303.12712.pdf
有趣的是,这篇火爆的论文还被人发现有大量删减,因此有人找出了未删节版论文。
从未删减版本中,这个博主也扒出了大量隐藏的细节,如 GPT-4 的内部名称为 DV-3,实际上也是该论文的隐藏第三作者,后被删除;这些微软的研究人员对 GPT-4 的技术细节似乎了解也并不多。此外博主也透露这篇论文发布时删除了有关毒性内容的部分(防止给 OpenAI 造成负面?)。
我们下面粘贴了该博主的 Twitter 线程,感兴趣的可以查看。

Twitter thread:https://twitter.com/DV2559106965076/status/1638769434763608064
回到文章本身。
根据文章所认定的 AGI,是具体的拥有推理、计划、解决问题、抽象思维、理解复杂思想、快速学习和从经验中学习的能力。从这些能力出发,论文进行了有趣的实验和评测。
论文分为 10 个章节:第一章为总括部分;第二章介绍了多模态,主要和视觉生成内容相关;第三章代码,根据指令生成代码、理解现有代码;第四章数学能力;第五章与世界的交互;第六章与人类的交互;第七章判别力;第八章 GPT-4 局限性;第九章社会影响;第十章未来方向及结论。
下面我们通过具体的示例,看看 GPT-4 是不是真的迈进了 AGI 时代。
多模态和跨学科组成
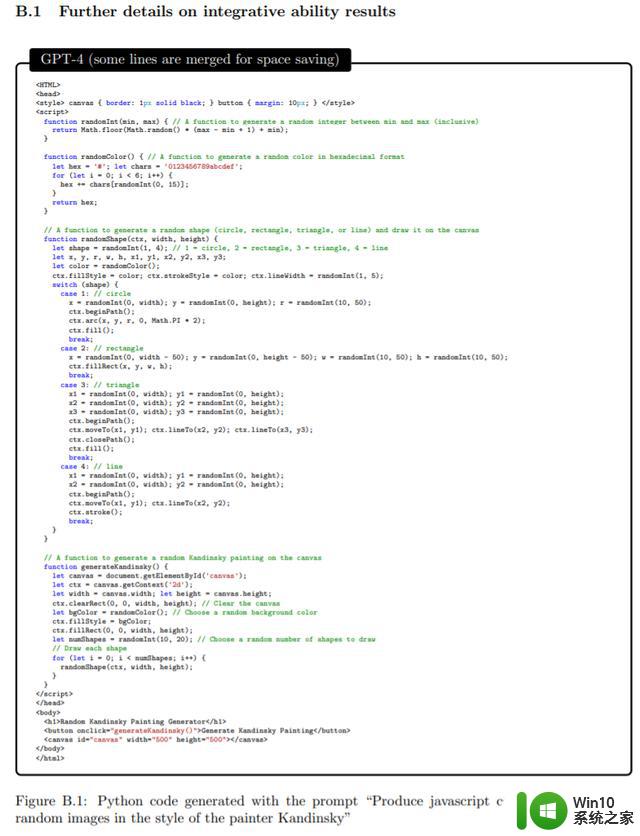
为了测试模型将艺术与编程相结合的能力,该研究要求 GPT-4 用 javascript 写一段代码,以生成康定斯基风格的随机图像,下图第一张为 Wassily Kandinsky 创作的,第二张和第三张分别由 GPT-4 和 ChatGPT 生成的:

下面为 GPT-4 代码实现过程:
进行视觉概念理解:在这个作图任务中, 输入提示让模型结合字母 Y、O、H 的形状来画一个人。其实在 GPT-4 的训练过程从没有关于字母形状的认识,只能从相关训练数据中、模糊地学习到字母与一些特定形状有关。结果显示 GPT-4 生成的结果还不错:

用于草图生成:GPT-4 还能与 Stable Diffusion 进行结合。下图为 3D 城市建模截图,输入提示有一条河流从左到右流淌、河的旁边建有金字塔的沙漠、屏幕底部有 4 个按钮,颜色分别为绿色、蓝色、棕色和红色。下面是生成结果:

你还能要求 GPT-4 用 ABC 记谱法生成和修改曲调:

编程能力
GPT-4 有非常强大的编程能力,包括根据指令编写代码和理解现有代码。该研究具体测试了 GPT-4 在编程方面的能力。
代码编写
下图 3.1 是一个让 GPT-4 写 python 函数的例子,该研究使用 LeetCode 在线判断代码是否正确。

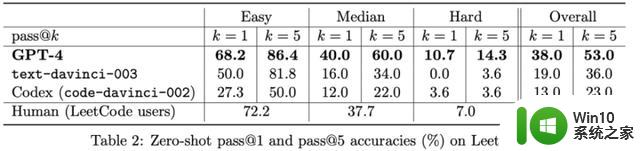
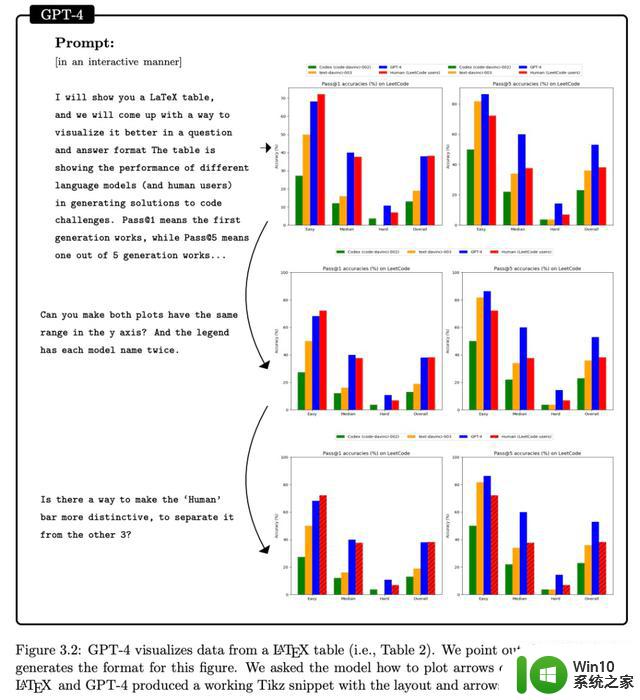
然后,该研究让 GPT-4 将上表 2 中 LeetCode 上的准确率数据可视化为图表,结果如下图 3.2 所示。
前端 / 游戏开发
如下图 3.3 所示,该研究让 GPT-4 用 JavaScript 在 HTML 中编写 3D 游戏,GPT-4 在零样本的情况下生成了一个满足所有要求的游戏。

深度学习编程
为深度学习编写代码需要数学、统计学知识,并熟悉 PyTorch、TensorFlow、Keras 等框架和库。如下图 3.4 所示,研究者要求 GPT-4 和 ChatGPT 编写自定义优化器模块,该任务对于人类深度学习专家来说也是具有挑战性的。研究者为 GPT-4 和 ChatGPT 提供了自然语言描述,其中包括一系列重要的操作,例如应用 SVD 等等。

此外,该研究还测试了 GPT-4 把代码转换成 LaTex 公式的能力,结果如下图 3.5 所示。

在理解代码方面,该研究尝试让 GPT-4 和 ChatGPT「读懂」一段 C/C++ 程序,并预测程序的输出结果,二者的表现如下:

然后,该研究让 GPT-4 解释了一段 Python 代码:

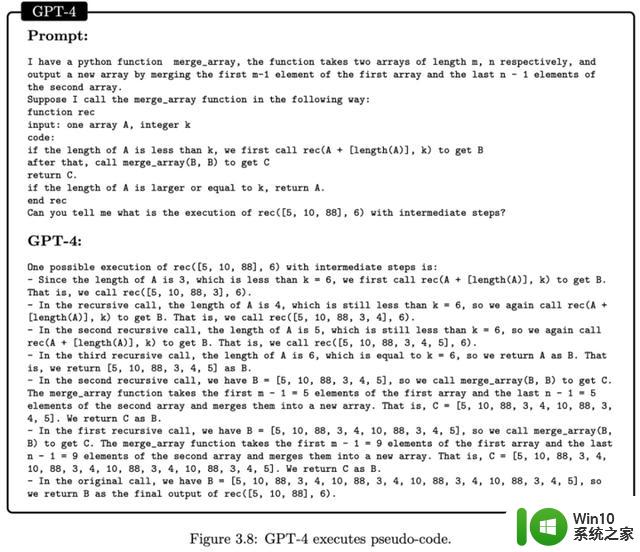
还有解释一段伪代码:
数学能力
一直以来,大型语言模型的数学能力似乎一直不是很好。那么 GPT-4 在这方面表现如何呢?本文经过一系列评测,结果表明 GPT-4 相比以前的模型在数学方面有了质的飞越,但是离专家水平还差得很远,不具备数学研究的能力。
在与 ChatGPT 的对比中, GPT-4 成功的生成了解决方案,而 ChatGPT 生成了错误答案:

在 AP 问题上,GPT-4 vs ChatGPT 对比结果。GPT-4 使用了正确的方法,不过由于计算错误导致最终答案错误,而 ChatGPT 产生了一个不连贯的论点。

此外,本文还测试了 GPT-4 使用数学思维和技术来解决现实问题的能力:下图展示了 GPT-4 如何成功地为一个需要广泛跨学科知识的复杂系统构建合理的数学模型,而 ChatGPT 未能取得有意义的进展。

由于论文内容长达 154 页,本文只对评测结果进行了大量展示,想要了解更多内容,读者可以参考原论文。
最后附上论文目录: