微软发布VASA-1:单张照片生成超现实真人视频,性能领先SOTA
现在 Microsoft Research 推出了VASA-1项目,同样是单张人像照片+语音音频=超现实的说话脸视频,但是性能SOTA!
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
VASA-1 可实现精确的唇声同步,逼真的面部行为,自然的头部运动,并支持实时生成!

据作者报道,该 VASA-1 不仅能够产生与音频同步的嘴唇动作,而且还能够捕捉到大量的面部细微差别和自然的头部动作,从而有助于感知真实性和人物状态。
,时长00:15
可以看到表情非常到位,特别是那灵活的小眼神!
相比之前的高启强普法视频,眼神、眉毛的动作显然要自然很多。
,时长00:17
更好的可控性VASA-1 的一个显著的特性是它可以接受可选信号作为条件,如主眼睛注视方向和头部距离,以及情绪偏移。这不仅增强了可玩性,重要的是动画效果更加自然!
,时长00:12
▲不同主注视方向(前、左、右、上)下的生成结果
,时长00:12
▲不同头距尺度下的生成结果
,时长00:11
▲不同情绪(分别为中性、快乐、愤怒、惊讶)下的生成结果
非常优秀的分布外泛化能力对于分布外的照片,比如油画、动漫中的人物,也一样可以让他或自然或鬼畜的说话!
,时长00:22
,时长01:17
,时长00:15
实时生成高质量内容不仅生成的效果非常逼真,VASA-1更是支持在离线批处理模式下以45fps的速度生成512x512大小的视频帧,在在线流媒体模式下可以支持高达40fps的视频帧,前延迟仅为170ms!
,时长00:34
官方的展示demo中丝滑的生成过程以及丰富的可编辑选项都能看出这项工作的成熟度,真是把吃瓜群众都给看急眼了,究竟啥时候才能玩啊。
什么是VASA-1区别于以往的方法,VASA-1不直接生成视频帧,而是根据声音和其他信号在潜在空间中生成整体面部动态和头部运动。
VASA-1 的面部解码器将这些动作潜在编码生成视频帧,同时也将从输入图像中提取的外观和身份特征作为输入。
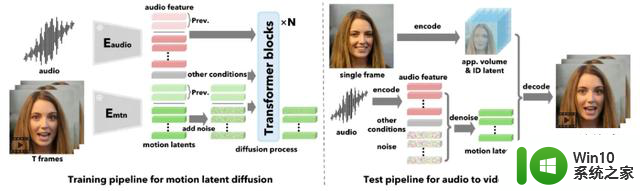
在论文中,作者还研究了音频和头部姿态之间的同步性测量问题,并提出了一种新的度量方法,称为“Contrastive Audio and Pose Pretraining”(CAPP)分数。
据作者介绍,这个方法受到了CLIP模型的启发,它通过联合训练一个姿态序列编码器和一个音频序列编码器来工作,其目标则是预测输入的姿态序列和音频是否配对。其中的音频编码器是基于一个预训练的Wav2Vec2网络初始化的,而姿态编码器是一个随机初始化的6层 transformer。
该 CAPP模型在大约2000小时的真实生活音频和姿态序列上进行了训练,并且展示了强大的能力来评估音频输入和生成的姿态之间的同步程度。
或者正是通过这种音频和头部姿态的对齐预训练才使得 VASA-1具有这么逼真的生成效果吧!
怎么还不开源?微软表示,在还不能避免技术滥用的情况下,他们不打算发布在线演示、API、产品、其他实现细节或任何相关产品,直到确定该技术将被负责任地使用。或者这也是阿里的 EMO 迟迟没有更新 github 的原因吧?那为啥腾讯就发布了捏?