ChatGPT真实参数只有200亿,网友惊呼:微软将开源?
在阅读此文之前,麻烦您点击一下“关注”,既方便您进行讨论和分享,又能给您带来不一样的参与感,感谢您的支持。
标题:技术革新的新潮:深入探究微软新研究的震撼与启示导语:近日,一个关于人工智能的新突破引发了行业的热烈讨论。一个微软研究团队发布的论文不仅公开了一个意外的秘密,而且介绍了一种创新的编码模型。这不仅仅是关于参数的数量,更是关于技术如何以更少的资源达到前所未有的效果。
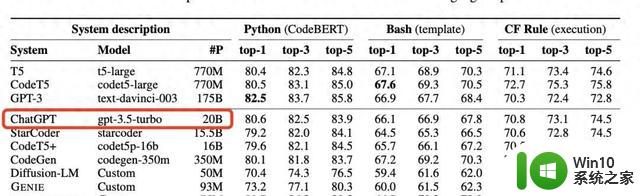
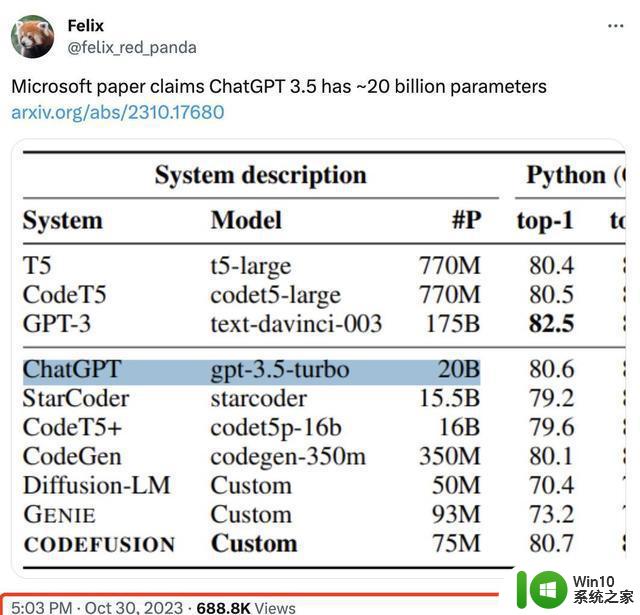
正文:整个人工智能社区最近被一个发现搅动了,讨论的焦点是一个看似平常的统计图表。微软的一篇新论文意外透露了一个信息:一个业界领先的大模型——被广泛应用的ChatGPT——可能只拥有200亿的参数量,远低于人们预期的规模。

这一数字一经公布,迅速在全球范围内引起了轩然大波。网络上的热议中,有些人怀疑是否是一个拼写错误。这一怀疑背后,是对OpenAI以往对大模型保密态度的理解,也反映出对未来可能开源的期待。

而这并非个例,在GitHub Copilot的API中,也有人发现了暗示着GPT-4更新的线索。这一切加起来,似乎在向我们预示着某种新的变革即将到来。
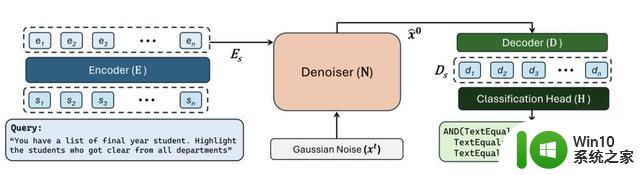
那么,这篇引发广泛关注的论文具体包含了哪些内容呢?论文不仅泄露了“秘密”,更重要的是,它首次介绍了使用扩散模型进行代码生成的新方法。这种方法对代码生成领域来说,是一种革命性的尝试。

微软的研究员们设计了一个名为CODEFUSION的编码-解码架构。它的工作方式类似于一种编译过程,将自然语言的输入转化为连续的表示,再通过Diffusion模型进行迭代去噪处理。这一创新架构的目标是提高代码生成的准确性,并在代码的多样性与质量之间找到一个更好的平衡。
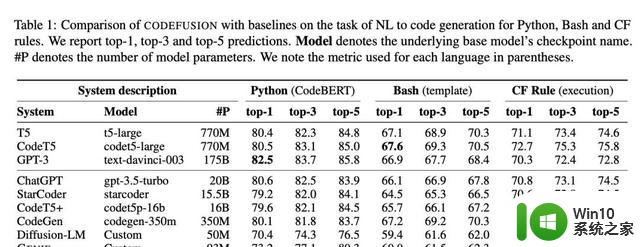
在三个不同的编程任务上对CODEFUSION进行了测试,包括Python、Bash和Excel的条件格式化。结果令人瞩目,即使是7500万参数的CODEFUSION,其表现也能媲美200亿参数的GPT-3.5-turbo,并在代码的多样性上有了显著提高。

相比于传统的自回归模型和纯文本生成模型,CODEFUSION在生成语法正确的代码方面表现得更为出色。它在保持精确度的同样地,提供了更多样化的编码选择。尤其是在生成前三名和前五名准确代码的能力上,CODEFUSION超过了现有的先进系统。
这一发现原本只是对性能的常规比较,却在技术社区引起了巨大的反响。有人甚至提出了阴谋论,认为这可能是OpenAI有意为之的开源“前菜”。考虑到已经有不少模型追赶上来,以及早在今年5月就有报道称OpenAI准备开源新的语言模型,这一猜测并非完全没有根据。
更有趣的是,早在今年2月份的一篇福布斯报道中,就已经提到了ChatGPT只有200亿参数的说法。尽管如此,那时这一消息并未引起广泛关注,直到如今这一波讨论的兴起。
结语:这篇重新构建的文章不仅提供了技术的新视角,还激起了对未来的深思。微软的新研究不仅仅揭示了一个关于模型参数量的惊人事实,它更是一种对现有AI开发方法的挑战和创新。这标志着我们正在步入一个新的时代,在这个时代中,技术的效率和创新将比单纯的规模更为重要。随着行业对这些新发现的深入探讨,我们可以预见,这将对未来的技术发展和开源文化产生深远的影响。


标题:技术革新的新潮:微软研究的震撼与启示导语:近日,一篇由微软研究团队发布的论文引发了人工智能领域的广泛讨论。不仅揭示了一个令人意外的模型参数量秘密,还带来了一种革命性的编码模型。这一发现不仅关乎规模,更涉及技术如何以更少的资源实现卓越的效果。
正文:整个人工智能社区最近被一项发现搅动,一个看似普通的统计图表成为了焦点。微软的这篇新论文揭示了一个惊人的信息:业界广泛应用的ChatGPT可能只包含着200亿参数,这一数字远低于人们的预期。这一揭示在全球范围内引发了广泛的争议,有些人甚至怀疑这是否是拼写错误,反映了对OpenAI以往对大模型保密的不解与期待未来的开源。
此外,GitHub Copilot的API中也暗示着GPT-4的更新,这一线索进一步加深了行业对未来的期望,似乎在暗示着某种新的技术变革即将到来。这一连串的迹象似乎在为一个新的技术时代的到来铺平道路。
那么,这篇备受关注的论文到底包含了哪些内容呢?该论文不仅透露了参数规模的“秘密”,更为重要的是,首次介绍了使用扩散模型进行代码生成的全新方法。这种方法在代码生成领域具有革命性意义。
微软的研究员们设计了一个名为CODEFUSION的编码-解码架构,类似于编译过程,将自然语言输入转化为连续的表示,然后通过Diffusion模型进行迭代去噪处理。该架构的目标是提高代码生成的准确性,找到代码多样性与质量之间的更好平衡。
CODEFUSION在三个不同的编程任务上进行了测试,包括Python、Bash和Excel的条件格式化。结果令人瞩目,即使是7500万参数的CODEFUSION,其表现也能媲美200亿参数的GPT-3.5-turbo,且在代码多样性方面有了显著提高。相较于传统的自回归模型和纯文本生成模型,CODEFUSION在生成语法正确的代码方面表现更出色。提供更多样化的编码选择,特别在生成前三名和前五名准确代码的能力上超越了现有的先进系统。
这一发现原本只是性能比较的一部分,但在技术社区中引发了巨大的反响。有人提出了开源“前菜”的阴谋论,考虑到不少模型已经在迎头赶上,以及OpenAI计划在未来开源新的语言模型,这一猜测也不无道理。值得注意的是,早在今年2月的一篇福布斯报道中就提到了ChatGPT只有200亿参数的说法,但那时没有引起广泛关注,直到近期的讨论才愈发热烈。
结语:这篇论文提供了技术的新视角,同时挑战和创新了现有的AI开发方法。它不仅揭示了有关模型参数量的惊人事实,更预示着我们正迈入一个新的技术时代,其中技术的效率和创新将比单纯的规模更为重要。随着行业对这些新发现的深入探讨,我们可以预见,这将对未来的技术发展和开源文化产生深远的影响。这一发现不仅令人震撼,也为技术领域的未来开启了新的篇章。